Spring Cloud Contract 1.0.0.M1 Released
I’ve just published an article at the Spring blog about Spring Cloud Contract 1.0.0.M1 Release. Check out the new project formerly known as Accurest!
Accurest becomes part of the Spring Cloud Contract
I’m extremely happy to announce that we have successfully rebranded the Accurest project. It’s officially become part of the Spring Cloud Contract initiative. Ladies and Gentlemen please welcome the new projects:
A little bit of history
Accurest was created because of lack of an easy-to-use tool for doing Consumer Driven Contracts. From our production experience the biggest problem was lack of verification that the defined contract actually does what it says it does. We wanted to ensure that from the contract automatically tests are generated so that we can have a proof that the stubs are reliable. Since there was no such tool the first commit of Accurest took place on 12/2014. The very idea and its implementation was initially set by Jakub Kubrynski and me. The last available version of Accurest was 1.1.0 released on 06/2016 (the docs for the old version are available here). During these 19 months a lot of feedback has been gathered. The tool has received a lot of very good reception and that made us want to work even harder. Many times we have decided to decrease the time required for sleeping so as to fix a bug or develop a new feature in Accurest.
Notable features
Speaking of features, especially quite a few of them definitely makes Accurest stand out on the “market” of Consumer Driven Contract (CDC) tooling. Out of many the most interesting are:
- Possibility to do CDC with messaging
- Clear and easy to use, statically typed DSL
- Possibility to copy paste your current JSON file to the contract and only edit its elements
- Automatic generation of tests from the defined Contract
- Stub Runner functionality - the stubs are automatically downloaded at runtime from Nexus / Artifactory
- Spring Cloud integration - no discovery service is needed for integration tests
For more information check out my posts about Stub Runner, Accurest Messaging or just read the docs.
Spring Cloud Contract
In Pivotal we came to the conclusion that Accurest could become an interesting addition to our Spring Cloud tooling. Due to the increased interest of the community in the Consumer Driven Contracts approach we’ve decided to start the Spring Cloud Contract initiative.
Accurest became Spring Cloud Contract Verifier (note: the name might change in the future) but for the time being will remain in the Codearte repository. It’s becoming the part of Spring Cloud tooling as a mature tool with a growing community around it. Some arguments for that are that it has:
- a nice AsciiDoc documentation that was completely rewritten following users’ feedback
- active Gitter channel where we try to immediately answer any support questions
- Over 80 stars on Github and counting ;)
Since we believe very much in the Consumer Driven Contract approach we also want to do the library in a Client Driven way. That means that we (server side) are very open to your feedback (consumer side) and want you be the main driver of changes in the library.
Credits
The Accurest project would never come to life without the hard work of the Codearte developers (the order is random):
and obviously everybody who has ever commited something to the project.
Links
If you want to read more about Spring Cloud Contract Verifier just check out the following links.
- Spring Cloud Contract Verifier Github Repository
- Spring Cloud Contract Verifier Documentation
- Accurest Legacy Documentation
- Spring Cloud Contract Stub Runner Documentation
- Spring Cloud Contract Stub Runner Messaging Documentation
- Spring Cloud Contract Verifier Gitter
- Spring Cloud Contract Verifier Maven Plugin
Zero Downtime Deployment with a Database
I’ve just published an article at the Spring blog about Zero Downtime Deployment with a Database. So if you’re planning on doing zero downtime or blue/green deployment you’d better check out that article :) The code is available here on Github.
Accurest and Stub Runner 1.1.0.M3
Currently at the Spring Team we’re polishing our libraries for the upcoming final release of the Brixton train. It should happen soon :) Until then I’m spending a lot of my after work, free time on Accurest and Stub Runner.
Today’s post will be about the new stuff that you will be able to profit from in the upcoming 1.1.0 release of Accurest. Also you can profit from most of these features in the 1.1.0.M3 release.
I’ll just quickly go through the features but note that you can read about all of them in more depth in our documentation .
Name change
AccuREST started as a library used to stub HTTP calls. In the upcoming 1.1.0 release you will be able to stub messaging functionality too. That’s why the name changes to Accurest. That’s a fantastic name isn’t it? ;)
Also since branding is important, now instead of calling io.codearte.accurest.dsl.GroovyDsl you can call io.codearte.accurest.dsl.Accurest :)
Messaging support
It took me quite some time to do this but it was worth it :) Several sleepless nights and now you can profit from defining contracts for messaging. In HTTP we had client/stub side and server/test side. For messaging we added methods to help discern the differences:
publisherthe side for which the tests will be generatedconsumerthe side for which the messaging endpoints will be stubbed
Contract
There are 3 use cases from the message Producer’s point of view.
- something happens in my application and I’m producing an output message
- someone sends a message to destination (queue/topic), I’m listening to that message and will produce an output message somewhere else
- someone sends a message to destination (queue/topic), I’m listening to that message and will consume it without any message sending
Here you can see examples of contracts for those three situations (you can read more about it in the docs ):
Output triggered by a method
The output message can be triggered by calling a method (e.g. a Scheduler was started and a message was sent)
def dsl = Accurest.make {
// Human readable description
description 'Some description'
// Label by means of which the output message can be triggered
label 'some_label'
// input to the contract
input {
// the contract will be triggered by a method
triggeredBy('bookReturnedTriggered()')
}
// output message of the contract
outputMessage {
// destination to which the output message will be sent
sentTo('output')
// the body of the output message
body('''{ "bookName" : "foo" }''')
// the headers of the output message
headers {
header('BOOK-NAME', 'foo')
}
}
}
Output triggered by a message
The output message can be triggered by receiving a message.
def dsl = GroovyDsl.make {
description 'Some Description'
label 'some_label'
// input is a message
input {
// the message was received from this destination
messageFrom('input')
// has the following body
messageBody([
bookName: 'foo'
])
// and the following headers
messageHeaders {
header('sample', 'header')
}
}
outputMessage {
sentTo('output')
body([
bookName: 'foo'
])
headers {
header('BOOK-NAME', 'foo')
}
}
}
No output, only input
There can be only input without any output
def dsl = GroovyDsl.make {
description 'Some Description'
label 'some_label'
// input is a message
input {
// the message was received from this destination
messageFrom('input')
// has the following body
messageBody([
bookName: 'foo'
])
// and the following headers
messageHeaders {
header('sample', 'header')
}
}
}
Producer side
Here you can see an example of a JUnit generated test for the producer for the input / output scenario:
// given:
AccurestMessage inputMessage = accurestMessaging.create(
"{\\"bookName\\":\\"foo\\"}"
, headers()
.header("sample", "header"));
// when:
accurestMessaging.send(inputMessage, "input");
// then:
AccurestMessage response = accurestMessaging.receiveMessage("output");
assertThat(response).isNotNull();
assertThat(response.getHeader("BOOK-NAME")).isEqualTo("foo");
// and:
DocumentContext parsedJson = JsonPath.parse(accurestObjectMapper.writeValueAsString(response.getPayload()));
assertThatJson(parsedJson).field("bookName").isEqualTo("foo");
We’re sending a message to a destination called input. next we’re checking if there’s a message at the output destination. If that’s the case
we’re checking if that message has proper headers and body.
Consumer side
It’s enough to provide the dependency to proper Stub Runner module (check the next section for more information) and tell it which stubs should be downloaded. Yup, that’s it! Stub Runner will download the stubs and prepare stubbed routes.
Sometimes you’ll need to trigger a message somehow in your tests. That’s why we’ve provided the StubTrigger interface that you can inject! If you’re already familiar with Stub Runner Spring then you could use the StubFinder bean to find the URL of your dependency. Now StubFinder also extends the StubTrigger interface thus you don’t have to inject any additional beans in your tests.
There are multiple ways in which you can trigger a message:
Trigger by label
stubFinder.trigger('return_book_1')
Trigger by group and artifact ids
stubFinder.trigger('io.codearte.accurest.stubs:camelService', 'return_book_1')
Trigger by artifact id
stubFinder.trigger('camelService', 'return_book_1')
Trigger all messages
stubFinder.trigger()
Integrations
We provide the following out of the box integrations:
- Spring Integration
- Spring Cloud Stream
- Apache Camel
Also we provide all the building blocks to provide a custom integration.
Just by providing the proper dependency
// for Apache Camel
testCompile "io.codearte.accurest:accurest-messaging-camel:${accurestVersion}"
// for Spring Integration
testCompile "io.codearte.accurest:accurest-messaging-integration:${accurestVersion}"
// for Spring Cloud Stream
testCompile "io.codearte.accurest:accurest-messaging-stream:${accurestVersion}"
Your generated tests should just work.
Stub Runner Boot
I’ve added a new module of Stub Runner that operates on Spring Boot. Assuming that you’re using Spring Cloud Stream you can create a project that has 2 dependencies:
compile "io.codearte.accurest:stub-runner-boot:${accurestVersion}"
compile "io.codearte.accurest:stub-runner-messaging-stream:${accurestVersion}"
Now if you pass the proper Stub Runner Spring configuration e.g.:
stubrunner.stubs.ids: io.codearte.accurest.stubs:streamService
You will have a running app that exposes HTTP endpoints to
- trigger messages
- check the URLs of the registered WireMock stubs
Accurest Maven Plugin
Mariusz Smykuła has done a fantastic job by adding the Accurest Maven Plugin. Now you can add Accurest to your project that runs with Maven. But that’s not all since the Maven Plugin allows you to run the Accurest stubs using the accurest:run command!
Read the docs to know more!
Stub Runner changes
Messaging
With messaging coming as a feature I’ve added a bunch of messaging modules. You can read more about the Stub Runner messaging modules here
Fixed ports and versions of stubs
Another feature that was missing and is really valuable is that now you can explicitly say that you want a particular dependency to be started at a given port. This feature is available since version 1.0.7 but the stub id has been changed in 1.1.0.M4 so be warned ;)
The ids have changed because now you can provide the desired version of the stub that you want to download.
Via properties
Now you can provide the id of a stub like this:
groupId:artifactId:version:classifier:port
where version, classifier and port are optional.
- If you don’t provide the port then a random one will be picked
- If you don’t provide the classifier then the default one will be taken.
- If you don’t provide the version then the + will be passed and the latest one will be downloaded
Where port means the port of the WireMock server.
So if you provide your dependency like this:
stubrunner.stubs.ids: io.codearte.accurest.stubs:streamService:0.0.1-SNAPSHOT:stubs:9090,io.codearte.accurest.stubs:anotherService:+:9095
It will make Stub Runner:
- download a stub with groupId:
io.codearte.accurest.stubs, artifactId:streamService, version:0.0.1-SNAPSHOT, classifier:stubsand register it at port 9090 - download a stub with groupId:
io.codearte.accurest.stubs, artifactId:anotherService, latest version, default classifier (stubs) and register it at port 9095
Via fluent API
When using the AccurestRule you can add a stub to download and then pass the port for the last downloaded stub.
@ClassRule public static AccurestRule rule = new AccurestRule()
.repoRoot(repoRoot())
.downloadStub("io.codearte.accurest.stubs", "loanIssuance")
.withPort(12345)
.downloadStub("io.codearte.accurest.stubs:fraudDetectionServer:12346");
You can see that for this example the following test is valid:
then(rule.findStubUrl("loanIssuance")).isEqualTo(URI.create("https://localhost:12345").toURL());
then(rule.findStubUrl("fraudDetectionServer")).isEqualTo(URI.create("https://localhost:12346").toURL());
Technical changes
Apart from features we’ve done some technical refactoring.
Grape -> Aether
I’ve migrated the mechanism used to download dependencies from Groovy Grape to Aether. We had a lot of issues with Grape and Aether works very well for now. That’s a backwards incompatible change so if you had some custom Grape configuration then you’ll have to port it to Aether.
Dependencies fixed
We had some problems with explicit and transitive dependencies that got fixed. The Accurest jars should be smaller.
Summary
- A lot work was done around Accurest and CDC
- Quite soon we’ll release the 1.1.0 version
- You can use stubs of your dependencies that communicate over messaging
- You can use fixed ports and versions for your dependencies
- If you like the project star it on Github :) That will give us additional boost of energy to spend on coding instead of sleeping ;)
Links
Accurest docs updated
After a lot of sleepless nights I’ve finally migrated the Accurest Docs from Github’s Wiki to Asciidoctor. With that change the vast majority of our snippets is taken from the tests. Also thanks to that change it will be much easier to keep the docs up to date since the documentation lives together with the code.
Quite frankly recently when I didn’t code Spring Cloud Sleuth I did a lot around Accurest and messaging so stay tuned! For sure there will be a new post about Consumer Driven Contracts and Messaging.
JSON Assert 0.4.0 released
I’m pleased to announce that JSON Assert version 0.4.0 got released! The following feature has been added
Retrieving value basing on the JSON Path
Wouldn’t it be great to retrieve the value from the JSON via the JSON Path? There you go!
given:
String json = ''' [ {
"some" : {
"nested" : {
"json" : "with value",
"anothervalue": 4,
"withlist" : [
{ "name" :"name1"} ,
{"name": "name2"},
{"anothernested": { "name": "name3"} }
]
}
}
},
{
"someother" : {
"nested" : {
"json" : true,
"anothervalue": 4,
"withlist" : [
{ "name" :"name1"} , {"name": "name2"}
],
"withlist2" : [
"a", "b"
]
}
}
}
]
'''
expect:
JsonPath.builder(json).array().field("some").field("nested").field("json").read(String) == 'with value'
JsonPath.builder(json).array().field("some").field("nested").field("anothervalue").read(Integer) == 4
assertThat(json).array().field("some").field("nested").array("withlist").field("name").read(List) == ['name1', 'name2']
assertThat(json).array().field("someother").field("nested").array("withlist2").read(List) == ['a', 'b']
assertThat(json).array().field("someother").field("nested").field("json").read(Boolean) == true
The JsonVerifiable extends the JsonReader that allows you to call the read(Class<T> clazz) method to retrieve the value from the JSON basing on the JSON Path.
Contact
Remember that JSON Assert has its own Gitter channel so in case of questions do not hesitate to contact me there.
UpToDate Gradle Plugin migrated
Time for another release here at Too Much Coding blog! This time it will be a short post :) I’m happy to announce that the UpToDate Gradle Plugin has finally found a new home!
Introduction
Since my leaving the company owning the original UpToDate Gradle Plugin repository, the project is almost not maintained at all. For quite a long time any development was done mostly by me and actually I was the author of most of the its code (like in the case of Stub Runner ). That’s why I’ve decided to fork the code, repackage it and start versioning from 1.0.0.
What is UpToDate Gradle Plugin?
Gradle plugin that tells you what libs have new versions on Maven Central, so when you come back to a project, you know what you can update.
How to use it?
Step 1: Add dependency to Maven Central and to the plugin
buildscript {
repositories {
mavenCentral()
}
dependencies {
classpath 'com.toomuchcoding:uptodate-gradle-plugin:1.0.0'
}
}
Step 2: Add the plugin to your build (gradle.build)
apply plugin: 'com.toomuchcoding.uptodate'
And now you can run the plugin with
gradle uptodate
Step 3: Read the readme ;)
For more information just read the project’s Readme.
How to migrate to com.toomuchcoding:uptodate-gradle-plugin?
If you’re using the old version of the code just change
com.ofg
into
com.toomuchcoding
and that should be it :) Oh, and change the version. I’m starting versioning from 1.0.0.
I’ve got questions - where to contact you?
Talk to me at the project’s Gitter.
AccuREST Stub Runner Released
It’s been a good release time recently! I’m blogging here at Too Much Coding blog more about releases then about any concrete topics ;)
After releasing Spring Cloud Sleuth as a part of Brixton RC1 we have just released a version 1.0.4 of AccuREST. We’ve fixed a couple of bugs but we’ve introduced a couple of big features including:
- Maven plugin support
- Stub Runner functionality
This post will describe the latter feature in more depth.
Introduction
I’ve given quite a few talks about the library called Micro-Infra-Spring where I presented how you can profit from the Stub Runner functionality. Since my leaving the company owning that repository, the project is almost not maintained at all. For quite a long time any development was done mostly by me and actually I was the author of most of the Stub Runner’s code. Due to the aforementioned and the fact that Stub Runner is tightly coupled with AccuREST’s stub generation feature I’ve decided to migrate it to the AccuREST’s repository.
AccuREST recap
Stub Runner is tightly coupled with the concepts coming from AccuREST. For more information about AccuREST you can check my blog entries or check AccuREST project on Github. If you don’t have a clue what that is I’ll try to do a very fast recap.
AccuREST is a Consumer Driven Contracts verifier in which you define the contract of your API via a Groovy DSL. From that DSL, on the server side, tests are created to check if your contract is telling the truth. From the Stub Runner’s perspective more interesting is the client side. For the client side AccuREST generates WireMock stubs from the provided DSL so that the clients of that API can be provided with reliable stubs.
What is Stub Runner?
Now that we remember what AccuREST does we can take a look in more depth at Stub Runner. Let’s assume that we have a following flow of services (btw. this is a screenshot from Zipkin integrated with Spring Cloud Sleuth )
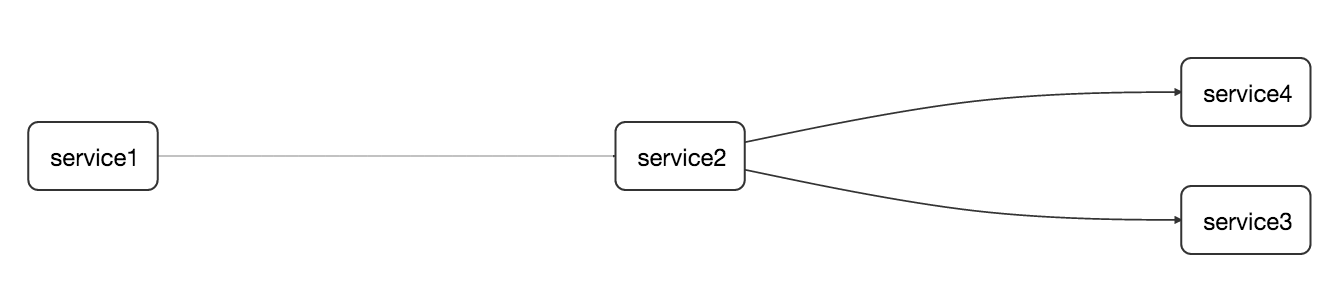
Let’s imagine ourselves as developers of the service2 - the one that calls service3 and service4. Since we’re doing the CDC (Consumer Driven Contracts) approach let’s assume that the stubs of service3 and service4 got already deployed to some Maven repository.
If I’m writing integration tests of service2 I’ll for sure have some points of interaction with service3 and service4. Most likely in the majority of cases I’ll just mock those interactions in my code but it would be valuable to have a real HTTP call done to the other application. Of course I don’t want to download both services and run them only for integration tests - that would be an overkill. That’s why the most preferable solution at this point would be to run the stubs of my collaborators.
Since I’m too lazy to do things manually I’d prefer the stubs to be automatically downloaded for me, the WireMock servers started and fed with the stub definitions.
And that’s exactly what Stub Runner can do for you!
How does it work?
Concept
Stub Runner at its core is using Groovy’s Grape mechanism to download the stubs from a given Maven repository. Next it unpacks them to a temporary folder. Let’s assume that you have the following structure of your WireMock stubs inside the stub JAR (example for a service3-stubs.jar)
├── META-INF
│ └── MANIFEST.MF
└── mappings
└── service3
├── shouldMarkClientAsFraud.json
├── notAWireMockMapping.json
└── shouldSayHello.json
Stub Runner will scan the whole unpacked JAR for any .json files. There is a convention that stub definitions are placed under the mappings folder. So it will pick shouldMarkClientAsFraud.json, notAWireMockMapping.json and shouldSayHello.json files.
Next, a WireMock instance is started for each dependency and every found JSON is attempted to be parsed as a WireMock stub definition. Any exceptions at this point are ignored (so assuming that notAWireMockMapping.json is not a valid WireMock definition, the exception will be suppressed). In our scenario 2 WireMock servers will be started - one for service3 and one for service4.
That way you don’t have to copy the stubs manually. The stubs are centralized since they are stored in a Maven repository. It’s extremely important cause Stub Runner downloads always the newest version of the stubs so you can be sure that your tests will break the moment someone does an incompatible change.
API
From the developer’s perspective there are only a handful of Stub Runner’s classes that should be used. In the majority of cases you will use the following ones:
StubFinder
An interface that allows you to find the URL of the started WireMock instance. You can find that URL by
passing the Ivy notation (groupId:artifactId) or just the artifactId - Stub Runner will try to take care of the rest.
interface StubFinder {
/**
* For the given groupId and artifactId tries to find the matching
* URL of the running stub.
*
* @param groupId - might be null. In that case a search only via artifactId takes place
* @return URL of a running stub or null if not found
*/
URL findStubUrl(String groupId, String artifactId)
/**
* For the given Ivy notation {@code groupId:artifactId} tries to find the matching
* URL of the running stub. You can also pass only {@code artifactId}.
*
* @param ivyNotation - Ivy representation of the Maven artifact
* @return URL of a running stub or null if not found
*/
URL findStubUrl(String ivyNotation)
/**
* Returns all running stubs
*/
RunningStubs findAllRunningStubs()
}
RunningStubs
A structure representing the already running stubs. Give you some helper methods to retrieve Ivy representation of a particular stub, find a port for a stub etc.
StubRunning
A contract for classes that can run the stubs:
interface StubRunning extends Closeable, StubFinder {
/**
* Runs the stubs and returns the {@link RunningStubs}
*/
RunningStubs runStubs()
}
StubRunner
Represents a single instance of ready-to-run stubs. It can run the stubs and will return the running instance of WireMock wrapped in RunningStubs class. Since it’s implementing StubFinder can also be queried if the current groupid and artifactid are matching the corresponding running stub.
BatchStubRunner
If you have multiple services for which you want to run the WireMocks with stubs it’s enough to use BatchStubRunner. It iterates over the given Iterable of StubRunner and executes the logic on each of them.
Running Stub Runner
In all the examples below let’s assume that the stubs are stored in the Maven repository available under https://toomuchcoding.com URL. As service2 I’d like to download the stubs of com.toomuchcoding:service3 and
com.toomuchcoding:service4 services.
Stub Runner as a fat JAR
How to use it?
Stub Runner comes with a main class (io.codearte.accurest.stubrunner.StubRunnerMain) which you can run with the following options:
-maxp (--maxPort) N : Maximum port value to be assigned to the
Wiremock instance. Defaults to 15000
(default: 15000)
-minp (--minPort) N : Minimal port value to be assigned to the
Wiremock instance. Defaults to 10000
(default: 10000)
-s (--stubs) VAL : Comma separated list of Ivy representation of
jars with stubs. Eg. groupid:artifactid1,group
id2:artifactid2:classifier
-sr (--stubRepositoryRoot) VAL : Location of a Jar containing server where you
keep your stubs (e.g. https://nexus.net/content
/repositories/repository)
-ss (--stubsSuffix) VAL : Suffix for the jar containing stubs (e.g.
'stubs' if the stub jar would have a 'stubs'
classifier for stubs: foobar-stubs ).
Defaults to 'stubs' (default: stubs)
-wo (--workOffline) : Switch to work offline. Defaults to 'false'
(default: false)
You can run that main class from IDE or build yourself a fat JAR. To do that just call the following command:
./gradlew stub-runner-root:stub-runner:shadowJar -PfatJar
Then inside the build/lib there will be a fat JAR with classifier fatJar waiting for you to execute.
Coming back to our example once the fat JAR is built I would just call the following command the retrieve the stubs of service3 and service4 from the Maven repository available at https://toomuchcoding.com.
java -jar stub-runner-1.0.4-SNAPSHOT-fatJar.jar -sr https://toomuchcoding.com -s com.toomuchcoding:service3:stubs,com.toomuchcoding.service4
When to use it?
Running Stub Runner as a main class makes most sense when you’re running some fast smoke tests on a deployed application where you don’t want to download and run all the collaborators of that application. For more rationale behind such an approach you can check my article about Microservice Deployment
Stub Runner JUnit Rule
How to use it?
You can use the Stub Runner’s JUnit rule to automatically download and run the stubs during your tests. The AccurestRule implements the StubFinder interface thus you can easily find the URLs of the services that you’re interested in.
This is how you could do it with Spock:
class SomeSpec extends Specification {
@ClassRule @Shared AccurestRule rule = new AccurestRule()
.repoRoot('https://toomuchcoding.com')
.downloadStub("com.toomuchcoding", "service3")
.downloadStub("com.toomuchcoding:service4")
def 'should do something useful when service3 is called'() {
given:
URL service3Url = rule.findStubUrl('com.toomuchcoding', 'service3')
expect:
somethingUseful(service3Url)
}
def 'should do something even more useful when service4 is called'() {
given:
URL service4Url = rule.findStubUrl('service4')
expect:
somethingMoreUseful(service4Url)
}
}
or with plain Java JUnit:
public class SomeTest {
@ClassRule public static AccurestRule rule = new AccurestRule()
.repoRoot("https://toomuchcoding.com")
.downloadStub("com.toomuchcoding", "service3")
.downloadStub("com.toomuchcoding:service4");
@Test
public void should_do_something_useful_when_service3_is_called() {
URL service3Url = rule.findStubUrl("com.toomuchcoding", "service3");
somethingUseful(service3Url);
}
@Test
public void should_do_something_even_more_useful_when_service4_is_called() {
URL service4Url = rule.findStubUrl("service4");
somethingMoreUseful(service4Url);
}
}
When to use it?
You can use this rule in any place you want to if we don’t provide any integration with an existing framework.
Stub Runner Spring
How to use it?
You can use the Stub Runner’s Spring configuration to download the stubs of your collaborators and run the WireMock server upon Spring context booting. We’re providing the StubRunnerConfiguration that you can import in your tests. In that configuration we’re registering a StubFinder bean that you can autowire in your tests.
Having the following application.yaml file:
stubrunner.stubs.repository.root: https://toomuchcoding.com
stubrunner.stubs.ids: com.toomuchcoding:service3:stubs,com.toomuchcoding.service4
This is how you could do it with Spock
@ContextConfiguration(classes = Config, loader = SpringApplicationContextLoader)
class StubRunnerConfigurationSpec extends Specification {
@Autowired StubFinder stubFinder
def 'should do something useful when service3 is called'() {
given:
URL service3Url = stubFinder.findStubUrl('com.toomuchcoding', 'service3')
expect:
somethingUseful(service3Url)
}
def 'should do something even more useful when service4 is called'() {
given:
URL service4Url = stubFinder.findStubUrl('service4')
expect:
somethingMoreUseful(service4Url)
}
@Configuration
@Import(StubRunnerConfiguration)
@EnableAutoConfiguration
static class Config {}
}
When to use it?
In your tests if you have Spring and don’t have Spring Cloud. Also you can add it in compile time (of course you would have to add some Spring profiles so as not to run it on production) to profit from a “developer” mode of running microservices. That means that if you boot up your application to click around it - all the stubs around you would have already been downloaded and started.
Stub Runner Spring Cloud
How to use it?
You can use the Stub Runner’s Spring Cloud configuration to profit from the stubbed collaborators when using Spring Cloud’s abstractions over service discovery and when you’re using Netflix Ribbon. Stub Runner Spring Cloud configuration is an AutoConfiguration so it’s automatically started for you.
Let’s assume that you’re referring to service3 as service3 in your code and to service4 as shouldMapThisNameToService4. That means that you’re using for example the @LoadBalanced RestTemplate in the following way (don’t use field injection as I do in this example!!):
@Component
class SomeClass {
@Autowired @LoadBalanced RestTemplate restTemplate
void doSth() {
// code...
String service3Response = restTemplate.getForObject('https://service3/name', String)
String service4Response = restTemplate.getForObject('https://shouldMapThisNameToService4/name', String)
// more code...
}
}
If the service Id that you’re using to call other services maps exactly to the name of the artifact Id in a Maven repository then you’re lucky and don’t have to do anything to find your running stubs. If however that’s not the case - don’t worry, you’ll just have to map it yourself.
The stubrunner.stubs.idsToServiceIds property is the root path to a map in which the key is the artifactID of the downloaded stub and the value is the serviceId used in the code.
Having the following application.yaml file:
stubrunner.stubs.repository.root: https://toomuchcoding.com
stubrunner.stubs.ids: com.toomuchcoding:service3:stubs,com.toomuchcoding.service4
stubrunner.stubs.idsToServiceIds:
service4: shouldMapThisNameToService4
This is how you could do it with Spock
@ContextConfiguration(classes = Config, loader = SpringApplicationContextLoader)
class StubRunnerConfigurationSpec extends Specification {
@Autowired SomeClass someClass
def 'should not explode'() {
when:
someClass.doSth()
expect:
noExceptionThrown()
}
@Configuration
@EnableAutoConfiguration
static class Config {}
}
When to use it?
When you’re using Spring Cloud. You can profit from Stub Runner Spring Cloud also in “developer” mode as presented in the Stub Runner Spring section.
Additional Configuration Options
You can set the default value of the Maven repository by means of a system property:
-Dstubrunner.stubs.repository.root=https://your.maven.repo.com
The list of configurable properties contains:
| Name | Default value | Description |
|---|---|---|
| stubrunner.port.range.min | 10000 | Minimal value of a port for a WireMock server |
| stubrunner.port.range.max | 15000 | Maximum value of a port for a WireMock server |
| stubrunner.stubs.repository.root | Address to your M2 repo (will point to local M2 repo if none is provided) | |
| stubrunner.stubs.classifier | stubs | Default classifier for the JARs containing stubs |
| stubrunner.work-offline | false | Should try to connect to any repo to download stubs (useful if there’s no internet) |
| stubrunner.stubs | Default comma separated list of stubs to download |
Summary
Stub Runner:
- Has already proven to be a very useful tool when doing CDC.
- Was battle tested and more companies are declaring their interest in using it.
- Helps you produce an API that should make both sides (server and the client) equally happy (or unhappy but still they’re both equal in their emotions ;) ).
- Is language / technology agnostic - you can run it as a fat JAR, use it with Spring, Guice or whatever you want.
- Helps you speed up the feedback cycle both from the API design and the compatibility perspective.
Links
JSON Assert 0.3.0 released
I’m pleased to announce that JSON Assert version 0.3.0 got released! The following features have been added
and in 0.2.2 the annoying warning message got removed
Building String JSON Path
Writing JSON Paths to assert JSON is no fun at all… That’s why JSON Assert was created in the first place. One doesn’t always want to use this library to perform assertions though. But what one wants to profit from is the fluent interface to create the JSON Path expression.
That’s why with 0.3.0 you can use the new class called JsonPath. It has a single static method builder()
with which you can… well… build the JSON Path. Remember to call jsonPath() to get its String value.
So for instance running this code:
JsonPath.builder().field("some").field("nested").field("anothervalue").isEqualTo(4).jsonPath()
would result in creating the following String JSON Path representation:
$.some.nested[?(@.anothervalue == 4)]
Other examples:
JsonPath.builder().field("some").field("nested").array("withlist").contains("name").isEqualTo("name1").jsonPath() === '''$.some.nested.withlist[*][?(@.name == 'name1')]'''
JsonPath.builder().field("some").field("nested").field("json").isEqualTo("with \"val'ue").jsonPath() === '''$.some.nested[?(@.json == 'with "val\\'ue')]'''
JsonPath.builder().field("some", "nested", "json").isEqualTo("with \"val'ue").jsonPath() === '''$.some.nested[?(@.json == 'with "val\\'ue')]'''
Pass fields as array of Strings
This is a small, handy feature that allows you to write less code. Often you iterate over a JSON that has plenty of fields. With the 0.3.0 release instead of writing:
assertThat(json).field("some").field("nested").field("json").isEqualTo("with \"val'ue")
you can write
assertThat(json1).field("some", "nested", "json").isEqualTo("with \"val'ue")
You get a method that allows you to traverse the JSON fields by passing an array of field names.
Contact
Remember that JSON Assert has its own Gitter channel so in case of questions do not hesitate to contact me there.
Spring Cloud Sleuth RC1 deployed
On the 24.03.2016 we’ve managed to move our release train called Brixton to the next station: RC1. I’m really happy about this cause it cost us a lot of energy but it was worth it!
I’m recently mostly focusing on the Spring Cloud Sleuth project and actually quite gigantic changes happened there since the M5 release. In this short post I’ll show you the rationale and describe briefly the features related to span naming and customizations related to span propagation.
What is Spring Cloud Sleuth?
For those who don’t know what Spring Cloud Sleuth is - it’s a library that implements a distributed tracing solution for Spring Cloud. You can check its code at Github.
We’re also trying to be aligned with the concepts, terminology and approaches present in the OpenTracing Project.
Distributed tracing terminology
I’ll quote the documentation to present some of the basic concepts of distributed tracing.
Span: The basic unit of work. For example, sending an RPC is a new span, as is sending a response to an RPC. Span’s are identified by a unique 64-bit ID for the span and another 64-bit ID for the trace the span is a part of. Spans also have other data, such as descriptions, timestamped events, key-value annotations (tags), the ID of the span that caused them, and process ID’s (normally IP address).
Spans are started and stopped, and they keep track of their timing information. Once you create a span, you must stop it at some point in the future.
Trace: A set of spans forming a tree-like structure. For example, if you are running a distributed big-data store, a trace might be formed by a put request.
Annotation: is used to record existence of an event in time. Some of the core annotations used to define the start and stop of a request are:
cs - Client Sent - The client has made a request. This annotation depicts the start of the span.
sr - Server Received - The server side got the request and will start processing it. If one subtracts the cs timestamp from this timestamp one will receive the network latency.
ss - Server Sent - Annotated upon completion of request processing (when the response got sent back to the client). If one subtracts the sr timestamp from this timestamp one will receive the time needed by the server side to process the request.
cr - Client Received - Signifies the end of the span. The client has successfully received the response from the server side. If one subtracts the cs timestamp from this timestamp one will receive the whole time needed by the client to receive the response from the server.
Ok since now we’re on the same page with the terminology let’s see what’s new in Sleuth.
Span creation and naming
Rationale
A really big problem that is there in the distributed tracing world is the issue related to naming spans. Actually that topic can be looked at from two angles.
First one is related to what the name of the span should look like. Should be a long and descriptive name or quite the contrary? As we write in the documentation:
The name should be low cardinality (e.g. not include identifiers).
Finding the name for the span is not that big of a problem from library’s perspective. You just pass on to a span whatever the user provides. But what about the situations in which some operation is deferred in time? Or scheduled at certain intervals?
Second one is related to a bigger issue: for the sake of consistency of passing tracing data, should we enforce creating spans? Should we be eager with that or allow the user to control span creation? Cause in that way we can have a problem how to name this artificial instance.
For RC1 we’ve decided that we will be eager in creating span names - but we will come back to the topic in the future releases.
Naming spans
Ok so we know the why, now let’s move to the how… There is quite a lot of instrumentation going on in Sleuth so sometimes the names of spans could sound artificial (e.g. async for asynchronous operations). When talking about runnables and callables often you’re dealing with code similar to this one:
Runnable runnable = new Runnable() {
@Override public void run() {
// perform logic
}
});
Future<?> future = executorService.submit(runnable);
// ... some additional logic ...
future.get();
What the Runnable is an operation that you would like to wrap in a span. What should be the name of that span? How can you pass it to the Tracer so that the span name is set?
To answer those issues we’ve introduced two approaches
- a
@SpanNameannotation for an explicit class that implementsRunnableorCallable toString()method resolution of an anonymous instance of either of those interfaces
Most likely in the future releases @SpanName or its modification will be used more heavily to provide explicit names of spans.
Anyways examples could look like those in the documentation. Example for @SpanName annotated class:
@SpanName("calculateTax")
class TaxCountingRunnable implements Runnable {
@Override public void run() {
// perform logic
}
}
and an anonymous instance:
new TraceRunnable(tracer, spanNamer, new Runnable() {
@Override public void run() {
// perform logic
}
@Override public String toString() {
return "calculateTax";
}
});
Both will have the same span name. Remember that both Runnables should be wrapped in a TraceRunnable instance.
Customization of span propagation
It’s pretty obvious that there’s a lot of companies that have already created some form of distributed tracing instrumentation. In Spring Cloud Sleuth we’re expecting the tracing headers to be containing certain names like X-B3-TraceId for the trace id containing headers or X-B3-SpanId for the span related one.
One of the first issues that we’ve created was related to support configurable header names but actually we’ve developed it quite late. Anyways with RC1 it’s possible to customize Sleuth in such a way that it’s compatible with your system’s nomenclature. Let’s define two terms before we go any further - Injector and Extractor.
Injectors
In Spring Cloud Sleuth an Injector is actually a functional interface called SpanInjector. It has the following method:
void inject(Span span, T carrier);
Its purpose is to take whatever is necessary from a span and
inject it to the carrier. Let’s assume that in your system you don’t set the headers for trace id with the name X-B3-TraceId but you call it correlationId and mySpanId for X-B3-SpanId. Then you would have to override the behavior of Sleuth by registering a custom implementation of the SpanInjector. Let’s look at the following snippets from the documentation:
class CustomHttpServletResponseSpanInjector implements SpanInjector<HttpServletResponse> {
@Override
public void inject(Span span, HttpServletResponse carrier) {
carrier.addHeader("correlationId", Span.idToHex(span.getTraceId()));
carrier.addHeader("mySpanId", Span.idToHex(span.getSpanId()));
// inject the rest of Span values to the header
}
}
Note that this approach will work with Zipkin only if your values that you’re passing are Zipkin-compatible. That means that the IDs are 64bit numbers.
Also you may wonder why do we convert values using Span.idToHex. We’ve decided that we want the values of ids in the logs and in the message headers to be the very same values as the one that you can later see in Zipkin. That way you can just copy the value and put it into Zipkin to debug your system.
Once you have the SpanInjector you have to register it as a bean with @Primary annotation as presented below:
@Bean
@Primary
SpanInjector<HttpServletResponse> customHttpServletResponseSpanInjector() {
return new CustomHttpServletResponseSpanInjector();
}
Extractors
In Spring Cloud Sleuth an Extractor is actually a functional interface called SpanExtractor. It has the following method:
Span joinTrace(T carrier);
Its purpose is to create a Span from the provided carrier. Let’s have the same assumption as with the SpanInjector and let’s consider a case where traceId header is named correlationId and spanId header is mySpanId. Then we customize the Spring context by providing our own implementation of the SpanExtractor:
class CustomHttpServletRequestSpanExtractor implements SpanExtractor<HttpServletRequest> {
@Override
public Span joinTrace(HttpServletRequest carrier) {
long traceId = Span.hexToId(carrier.getHeader("correlationId"));
long spanId = Span.hexToId(carrier.getHeader("mySpanId"));
// extract all necessary headers
Span.SpanBuilder builder = Span.builder().traceId(traceId).spanId(spanId);
// build rest of the Span
return builder.build();
}
}
Again note that we’re considering that the values are Zipkin compatible (64bit values for ids). Also note that we’ve assumed that the ids are sent in a hexadecimal form like they are presented in the Zipkin UI. That’s why we used the Span.hexToId method to convert it back to long again.
Summary
In this very short post you could see two quite big features available in the RC1 release. You can check Spring Cloud Sleuth documentation for more information about the integrations and configurations of Sleuth. Actually you can check all the things that have changed in the RC1 release by checking the closed issues and merged PRs.
In case of any questions do not hesitate to ping us on the Gitter channel or file an issue on Github.